OpenAI lanza GPTBot: el rastreador que recopilará datos públicos de Internet para entrenar modelos de inteligencia artificial. Deberás optar por no participar si no deseas que tu contenido en línea se utilice para el entrenamiento de IA.
Jose Antonio Lanz | Decrypt / Raquel Holgado | 20Minutos

Imagen editada por Naida Jazmin Ochoa para Arte es Ética
OpenAI se ha convertido en la empresa especializada en inteligencia artificial por excelencia. Desde que lanzó ChatGPT-3, muchas compañías se han sumado al boom del desarrollo de herramientas con este tipo de tecnología. Sin embargo, el modelo de lenguaje grande no es el único sistema que han creado, también tienen a DALL-E, un generador de imagen a partir de texto y, ahora, cuentan con GPTBot.
El nuevo proyecto de OpenAI es capaz de acceder a casi todos los contenidos de Internet, lo cual será ideal para el entrenamiento de los futuros modelos de IA que desarrollen. “El uso de GPTBot tiene el potencial de mejorar los modelos de IA existentes en aspectos como la precisión y la seguridad“, detallan en un post de la web de la marca.
Las principales quejas de los usuarios tienen que ver con los contenidos con derechos de propiedad intelectual a los que GPTBot accederá, a no ser que el creador manifieste que no quiere, de forma manual.
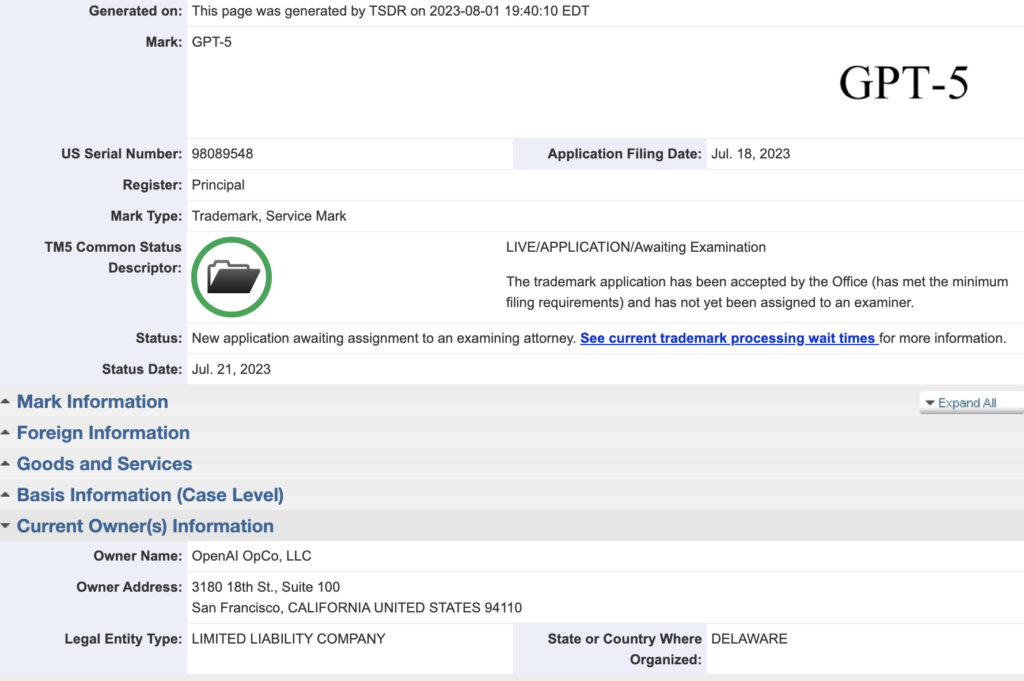
La empresa de Sam Altman ha lanzado este nuevo bot de rastreo web, GPTBot, para ampliar su conjunto de datos con la finalidad de entrenar su próxima generación de sistemas de IA, y al parecer la próxima iteración ya tiene un nombre oficial. La compañía ha registrado la marca “GPT-5”, insinuando un próximo lanzamiento, al tiempo que advierte a los editores web cómo mantener su contenido fuera de su enorme alcance.
OpenAI OpCo, LLC ha presentado una solicitud de marca “GPT-5” ante la Oficina de Patentes y Marcas de los Estados Unidos (USPTO). La solicitud, presentada el 18 de julio de 2023, está actualmente en trámite.

GPTBot será una especie de rastreador web de la firma para buscar datos públicos. Por muy preocupante que suene esto, OpenAI asegura que filtrarán las fuentes que requieran acceso a través de un muro de pago, eliminarán información personalmente identificable o texto que viole sus políticas.
La llegada de esta IA, pese a que no recopile información confidencial o de pago, ha recibido múltiples quejas por usar contenidos que podrían tener derechos de propiedad intelectual, como fotografías, vídeos, música, etc.
En Hacker News, algunos usuarios justificaron la decisión de OpenAI diciendo que debe recopilar todo lo que pueda si las personas quieren tener una herramienta de IA generativa capaz en el futuro. “Todavía necesitan datos actuales o sus modelos GPT quedarán atrapados en septiembre de 2021 para siempre”, dijo un usuario. Otro usuario más consciente de la privacidad argumentó que “OpenAI ni siquiera está citando en la moderación. Está creando una obra derivada sin citar, por lo tanto, la está oscureciendo”.
“El consentimiento no se otorga hasta que se indique explícitamente en forma afirmativa –opina uno de los internautas que debaten del asunto a través de HackerNews-. Intenta aplicar el concepto ‘suponga que sí inicialmente, hasta que le digan lo contrario’ para entrar en la casa de alguien o tocar el cuerpo de alguien y déjeme saber cómo funciona para ti”.
Según OpenAI, el rastreador web recopilará datos de acceso público de sitios web, evitando contenido pago, sensible y prohibido. Sin embargo, al igual que otros motores de búsqueda como Google, Bing y Yandex, el sistema es de exclusión voluntaria: por defecto, GPTBot asumirá que la información accesible es válida.
Para evitar que el rastreador web de OpenAI analice un sitio web, el propietario debe agregar una regla de “no permitir” a un archivo estándar en el servidor.
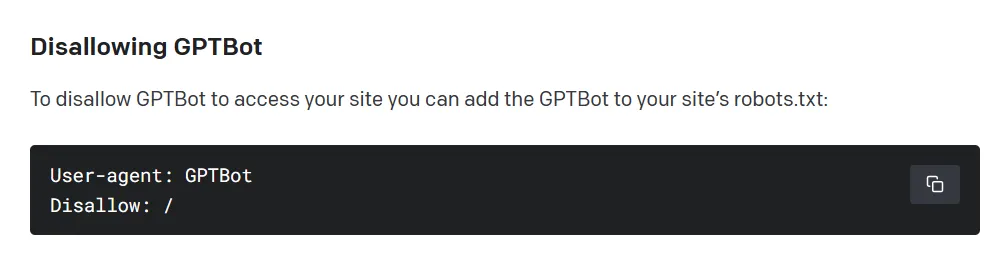
En un principio, los usuarios podrán restringir que GPTBot entre en sus webs de forma manual, pero si no muestran su rechazo, el sistema será capaz de acceder al contenido:
- Para identificar a GPTBot a través de su token de agente de usuario y su cadena de agente de usuario:
User agent token: GPTBot
Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
- Si desean evitar que GPTBot acceda a una web pueden agregarlo al archivo .txt:
User-agent: GPTBot
Disallow: /
- Es posible controlar el acceso de GPTBot a algunos espacios de la web mediante códigos específicos en el archivo robot .txt:
User-agent: GPTBot
Allow: /directorio-1/
Disallow: /directorio-2/
OpenAI también dice que GPTBot escaneará de manera preventiva los datos recopilados para eliminar información de identificación personal (PII) y texto que viole sus políticas.
Sin embargo, según algunos éticos de la tecnología, el enfoque de exclusión voluntaria aún plantea problemas de consentimiento.
El lanzamiento de GPTBot sigue las críticas recientes a OpenAI por recopilar datos sin permiso para entrenar Modelos de Lenguaje Grandes o Large Language Models (LLMs) como ChatGPT. Para abordar estas preocupaciones, la compañía actualizó sus políticas de privacidad en abril.
Esto podría representar un cambio en el énfasis inicial de OpenAI en la transparencia y la seguridad de la IA, pero no es sorprendente considerando que ChatGPT es el LLM más utilizado en el mundo, a pesar de un mercado cada vez más saturado y potente. El producto estrella de OpenAI, al igual que cualquier LLM, solo es tan bueno como la calidad de los datos utilizados para entrenarlo.
OpenAI necesita recopilar nuevos y mejores datos. Y necesita muchos de ellos.
Por otro lado, hay un LLM de código abierto, creado por el gigante de las redes sociales, Meta. El gigante tecnológico ha ofrecido su modelo de forma gratuita, siempre y cuando no seas un competidor ni una empresa demasiado grande. Meta no ha revelado qué conjuntos de datos utilizó para entrenar su modelo y qué información ha recopilado. Sin embargo, este enfoque permite a los usuarios ajustar el modelo utilizando sus propios conjuntos de datos.
Mientras que OpenAI se basa en todos sus datos recopilados para entrenar sus modelos y construir un ecosistema rentable en torno a sus herramientas de IA, Meta está tratando de construir un negocio rentable en torno a sus datos. Por lo tanto, Meta no solo los utiliza para crear mejores modelos, sino que también los comparte con terceros para que los utilicen.
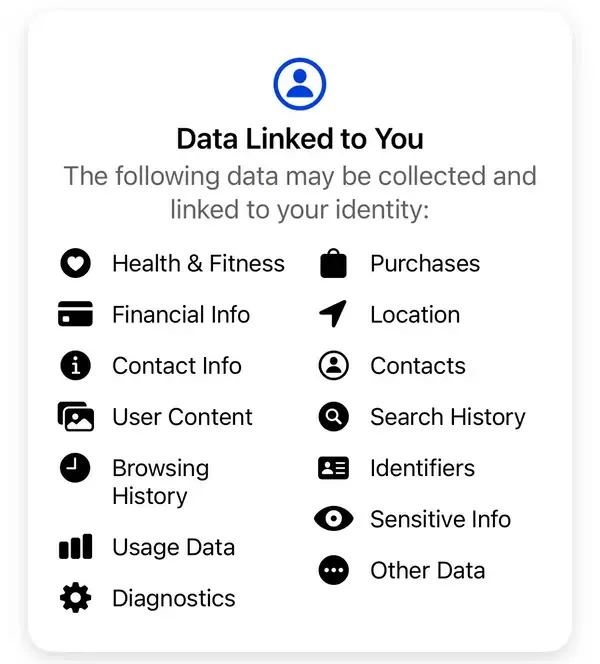
“No vendemos tu información. En cambio, según la información que tenemos, los anunciantes y otros socios nos pagan para mostrarte anuncios personalizados“, explica Meta. Según las divulgaciones de privacidad estándar de Meta, algunos de los datos que la empresa recopila incluyen compras, historial de navegación, identificadores, información financiera, contactos y otra información sensible no revelada, entre otros.
ChatGPT ahora cuenta con más de 1,5 mil millones de usuarios activos mensuales. Y la inversión de $10 mil millones de Microsoft en OpenAI parece previsora, ya que la integración de ChatGPT ha mejorado las capacidades de Bing.
Por ahora, OpenAI lidera el candente espacio de la IA, con los gigantes tecnológicos corriendo para intentar alcanzarlo. El nuevo rastreador web de la compañía puede mejorar aún más las habilidades de sus modelos. Pero la expansión de la recopilación de datos de internet también plantea preguntas éticas sobre los derechos de autor y el consentimiento.
A medida que los sistemas de IA se vuelven más sofisticados, equilibrar la transparencia, la ética y las capacidades seguirá siendo un acto de equilibrio complejo.
En resumen
1.- OpenAI lanza el rastreador web GPTBot, recopilando datos para entrenar GPT-5, su próxima generación de sistemas IA.
2.- El sistema recopila información pública, excluyendo contenido pago y sensible, pero plantea problemas éticos de consentimiento.
3.- La compañía registra la marca “GPT-5”, indicando un próximo lanzamiento, mientras compite en el espacio de IA con gigantes tecnológicos como Meta.
Pero ¿qué es un web crawler?
Fuente: Digital Guide IONOS
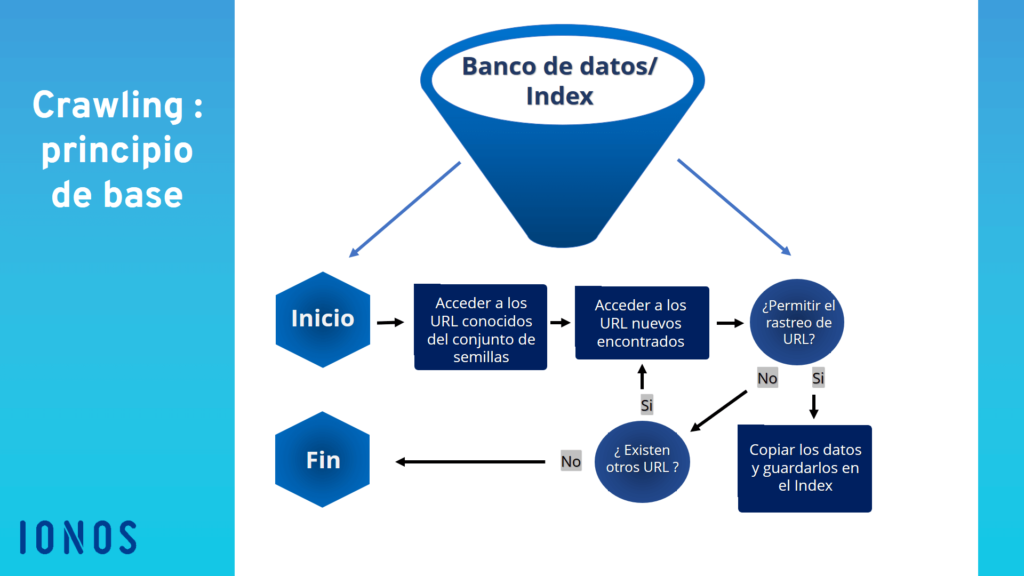
Los web crawlers son bots que buscan datos en Internet, analizan el contenido y guardan la información en índices y bases de datos para mejorar el rendimiento de los motores de búsqueda. Además, las arañas web recopilan datos de contacto y perfiles con fines de marketing.
Como estos bots de motores de búsqueda se mueven de forma tan precisa por todas las ramificaciones de Internet en busca de información, en español se los conoce como arañas web o rastreadores web. El primer web crawler se llamaba World Wide Web Wanderer y se basaba en el lenguaje de programación PERL. Este rastreador, implementado en 1993, medía el crecimiento del entonces todavía joven Internet y organizaba los datos recopilados en Wandex, el primer índice de Internet.
En 1994, al World Wide Web Wanderer le siguió el primer navegador, llamado Webcrawler, el motor de búsqueda más antiguo que aún existe en la actualidad. Gracias a las arañas web, los motores de búsqueda pueden mantener sus bases de datos actualizadas automáticamente, añadiendo nuevo contenido y sitios web al índice y eliminando el contenido obsoleto.
Los web crawlers son especialmente importantes para la optimización de motores de búsqueda o SEO (del inglés search engine optimization). Para las empresas, es fundamental familiarizarse con los diferentes tipos y funciones de arañas web para poder ofrecer un contenido optimizado para SEO en línea.
¿Cómo funciona un web crawler?
Al igual que los bots sociales y los chatbots, los web crawlers están compuestos por un código de algoritmos y scripts que establece unos comandos e instrucciones claros. El web crawler repite las funciones indicadas en el código de forma automática y continua.
Los web crawlers se desplazan por Internet a través de los hipervínculos que aparecen en los sitios web existentes. Evalúan palabras clave y hashtags, indexan el contenido y los URL de cada sitio web, copian páginas web y abren todos o solo algunos de los URL que encuentran para analizar nuevos sitios web. Además, comprueban que los enlaces y los códigos HTML estén actualizados.
Mediante el uso de herramientas especiales de análisis web, los web crawlers pueden evaluar diversos datos, como los enlaces clicados y las páginas visitadas, así como recopilar información en términos de minería de datos o compararlos de forma dirigida (por ejemplo, para portales de comparación).
Actualización 14 de Agosto 2023

Hablamos con Benjamin Harbakk, programador y artista, para consultarle su opinión y esto nos comentó:
NO es una forma garantizada de impedirlo, pero ES una forma de decir “no utilices mis cosas”. Esto PUEDE ser útil para batallas legales posteriores, y PUEDE detenerlas en el futuro. Pero se pierde un contexto muy importante:
- Los sitios ya rastreados NO serán eliminados de sus conjuntos de datos.
- Es probable que ya estén entrenando con sus datos
- Esto SOLO detendrá a OpenAI, no a otros bots de otras compañías de IA (y hay cientos de ellos emergiendo).
Pero creo que todavía vale la pena hacerlo.
Pero recomiendo que se añada otro bot al protocolo de exclusión, concretamente CCBot o el bot “Common Crawl”, ya que el 90% de los investigadores de IA que trabajan con texto utilizan Common Crawl Data (¡INCLUYENDO OpenAI!)
Déjeme mostrarle algo. Estos son los datos de entrenamiento para GPT-3:
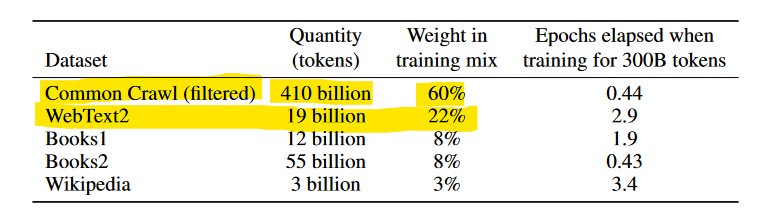
Lo entrenaron con Common Crawl, que básicamente ha indexado todo Internet.
No han dicho EN NINGÚN LUGAR que vayan a dejar de usar Common Crawl. Así que aunque BLOQUEES “GPTBot”, ellos siguen usando todo lo rastreado por “CCBot”, el bot de Common Crawl.
El propósito de robots txt es decirle a un webcrawler “Oye, puedes visitar estas páginas específicas, pero por favor no vayas a estos otros enlaces”. No es un “Bloqueo”, es simplemente una petición.
Si vas a usarlo, haz esto:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
User-agent: CCBot
User-agent: GPTBot
Disallow: /
La verdad es que no hay seguridad en Internet
Si cuelgas tu trabajo en tu propia web, otros lo volverán a colgar en sitios como Pinterest. A menudo, tú no eres quien controla tu sitio web (por lo que no puedes cambiar el documento robots.txt).
No hay seguridad pura, pero estas son algunas buenas prácticas para mantenerte lo más seguro posible:
1.- Ponle una marca de agua a tu trabajo, el entrenamiento de IA suele intentar filtrar las imágenes con marcas de agua, porque empeoran la IA. Esto necesita un tutorial, porque algunas marcas de agua son buenas, otras son malas.
2.- Usa Glaze antes de publicar. No publiques nada sin Glaze.
3.- Añade un Sello de “Copyright” a tu obra (sobre la imagen), así: © 2023 NOMBRE DEL ARTISTA
Esto no impide el entrenamiento, pero puede ayudar en batallas legales posteriores.
4.- Enviar solicitudes de Copyright DMCA takedown a los sitios web que alojan su contenido sin permiso. Esto te ayuda a controlar dónde está tu obra en internet, pero requiere mucho esfuerzo.
5.- Añade “CCBot” y “GPTBot” a tu robots.txt

También hablamos con Ben Zhao, profesor de informática
de la Universidad de Chicago, responsable del equipo desarrollador de Glaze, y esto nos comentó:
Sí, esto es real. OpenAI está haciendo esto y dijeron que respetarán robots.txt. Así que todo el mundo debería hacerlo. No es una garantía. Pero dado que OpenAI lo anunció públicamente, creo que debería ser medianamente fiable. Si se retractan de esta promesa (aún es posible), se vería muy mal para ellos.
Benjamin lo resumió perfecto. Lo único que añadiría es que las marcas de agua no hacen mucho. Pero está bien añadirlas.
Decir simplemente: “Haz esto y estarás a salvo” no es correcto. No hay ninguna garantía y los artistas deben tomar todas las precauciones. Incluso si OpenAI se comporta correctamente, hay más y más crawlers/bots en línea cada día, todos buscando raspar tu arte. Los artistas necesitan aplicar todas las protecciones razonables.