En la base de datos utilizada para entrenar a Stable Diffusion, MidJourney y otros productos de IA generativas hay imágenes con copyright de fotógrafos e ilustradores que no han dado su permiso para eso.
“Es alucinante”. Lo dice Santi Palacios, y no en el sentido positivo, cuando le muestro el plagio, o que al menos 15 de sus fotografías han sido usadas para entrenar a IA generativas de imágenes como Stable Diffusion o Midjourney. Palacios es un fotoperiodista independiente que publica en revistas y periódicos de todo el mundo, y ha ganado decenas de premios nacionales e internacionales.
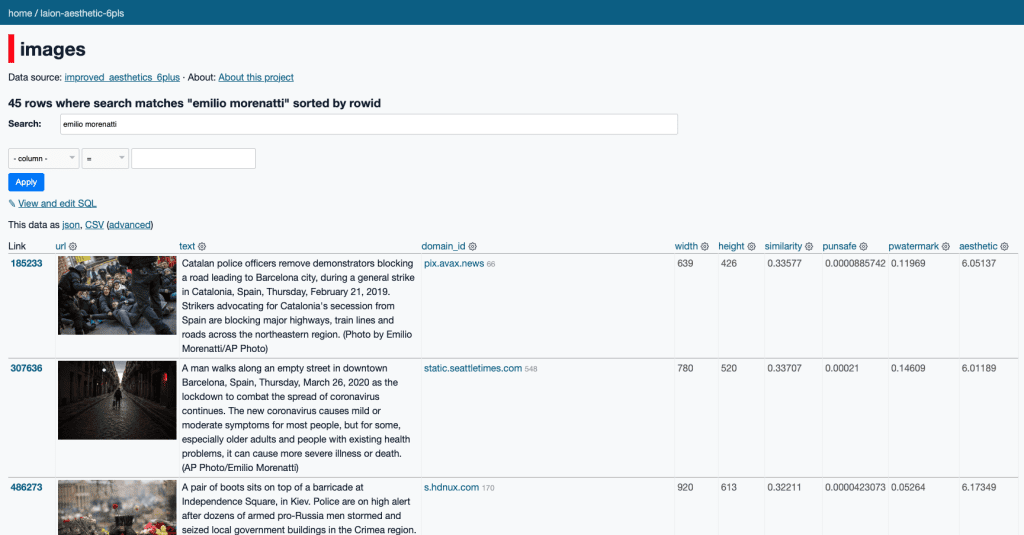
Emilio Morenatti, fotógrafo que acaba de ganar su segundo Pulitzer por ser parte del equipo que hizo la cobertura de Ucrania, también tiene fotos que han sido utilizadas para entrenamiento de una IA. Lo mismo que Anna Surinyach, Manu Brabo y Ana Palacios, fotoperiodistas españoles conocidos y prestigiosos que viven de su trabajo desde hace años. Ninguno sabía que imágenes de su autoría aparecen en el conjunto de datos usado para entrenar estos modelos, y ninguno ha dado consentimiento para estos usos sobre esas imágenes. “Primera noticia”, dice Surinyach.
No son los únicos. Fotografías de al menos 55 fotógrafos, artistas, o reporteros gráficos españoles y latinoamericanos aparecen este conjunto de datos: Chema Madoz, Javier Etxezarreta, Francisco Seco, Gervasio Sánchez, Pablo Tosco, Samuel Aranda, Susana Girón, Javier Corbalán, Marcos Brindicci, Iván Alvarado, entre ellos. La lista sigue y puede consultarse al final de este reportaje.
En muchos casos, el texto de los metadatos de las fotos, que también ha sido usado para entrenar el modelo, incluye el nombre de las agencias: EFE, European Pressphoto Agency (EPA), Reuters, Associated Press (AP), y Getty (que ha iniciado una demanda por copyright contra Stability AI, la empresa detrás de Stable Diffusion).
En los textos que identifican a las fotografías para los editores, 1.200 tienen la advertencia “editorial use only”, lo que significa que esas imágenes no pueden ser usadas para otra finalidad que la editorial. Muchas de ellas acotan también el país en el que está prohibido su uso, u otro tipo de limitaciones de licencias.
La demanda por plagio contra las IA generativas en EE.UU.
En enero de este año, tres artistas iniciaron una demanda colectiva en San Francisco contra Stability AI, DeviantArt y Midjourney por su uso de Stable Diffusion. Esta herramienta es una de las IA más conocidas del tipo texto-a-imagen, por la cual el usuario introduce una instrucción de texto descriptivo (prompt) y la IA genera imágenes.
La demanda sostiene que Stable Diffusion es una herramienta que remezcla las obras con copyright de millones de artistas cuyo trabajo ha sido utilizado para su entrenamiento. Una de las demandantes es Karla Ortiz, artista puertorriqueña que ha trabajado en proyectos de gran presupuesto en las industrias del cine, la TV y los videojuegos. En agosto de 2022, ella ya había encontrado obras similares a las de creadores que conocía en una web que vendía merchandising y NFT de esos autores. Para su sorpresa, esas obras “que se parecían mucho”, no habían sido creadas por ellos. Les escribieron, pero después de unos intercambios que ella describe como tensos, se cortó la comunicación.
Con la llegada de Stable Diffusion, Midjourney y otras IA generativas, Ortiz se encontró otra vez con el plagio en este tipo de prácticas. “Estas compañías dejaban que los usuarios utilizaran los nombres completos de artistas para generar imágenes, y descubrí que los datos usados para entrenar estos modelos estaban plagados del trabajo de muchos artistas que conocía, yo incluída”. Todo esto había sucedido sin el permiso de ninguno de ellos, o como se conoce en la industria cultural, ninguna de las tres Cs: consentimiento, crédito o compensación.
“Ví en internet un artículo que difundía una extensísima lista de movimientos pictóricos y nombres propios de artistas de toda la historia del arte, incluyendo a la contemporánea. Ahí, donde se ordenaba en cada fila con un número los nombres de artistas como Rembrandt, Michelangelo, Leonora Carrington, Dave McKean o Kim Jun Gi, estaba el mío”. En la otra punta del continente, en Buenos Aires, Santiago Caruso, ilustrador, descubre lo mismo. “Leí paralizado de terror, como quien viera a través de un monitor de seguridad a su doppelgänger entrando en la misma habitación para matarlo”.
Caruso, cuyo caso adelantamos en Newtral, ha mostrado evidencia de que su nombre ha sido usado como prompt más de 1800 veces en Midjourney desde septiembre de 2022 hasta febrero de 2023. “Un usuario de Night Café generó más de 100 imágenes con mi nombre que ofrece a la venta como NFT en Opensea”, añade.
De dónde salen las imágenes para entrenar las IA generativas
La demanda sigue adelante en San Francisco, tras la última moción de desistimiento por parte de las empresas denunciadas, un paso usual en este tipo de procesos. Muchos ojos, como los de Caruso o los de varios abogados españoles consultados por Newtral, que tienen clientes que pueden estar siendo afectados por este plagio de las IA generativas, están puestos sobre la futura sentencia. Para entrenar esas IA se ha tomado (o escrapeado) contenido de una gran parte de internet.
OpenAI, la empresa creadora de ChatGPT, dice que ha entrenado su IA de texto a imagen, DALL-E 2 con cientos de millones de imágenes, pero no ha publicado los datos. Esta compañía, que empezó siendo un laboratorio de investigación sin fines de lucro, mantuvo cierta transparencia hasta GPT-2, y por eso conocemos que obtuvo información de miles de sitios web (muchos de ellos con copyright) para entrenar ese modelo de lenguaje previo a GPT-3.
Por el contrario, Stable Diffusion ha sido transparente al respecto. Stability AI lo ha lanzado con una licencia muy permisiva y así otros programas lo han incorporado: Midjourney Beta, NightCafe y DreamStudio, una versión de Stable Diffusion empaquetada en una interfaz web que es de pago.
Un buscador de imágenes usadas por IA para entrenamiento
Así sabemos que Stable Diffusion fue entrenado con tres conjuntos de datos masivos recolectados de la web por LAION, una organización alemana sin fines de lucro que ha sido financiada por Stability AI, como ha dicho su mismo CEO.
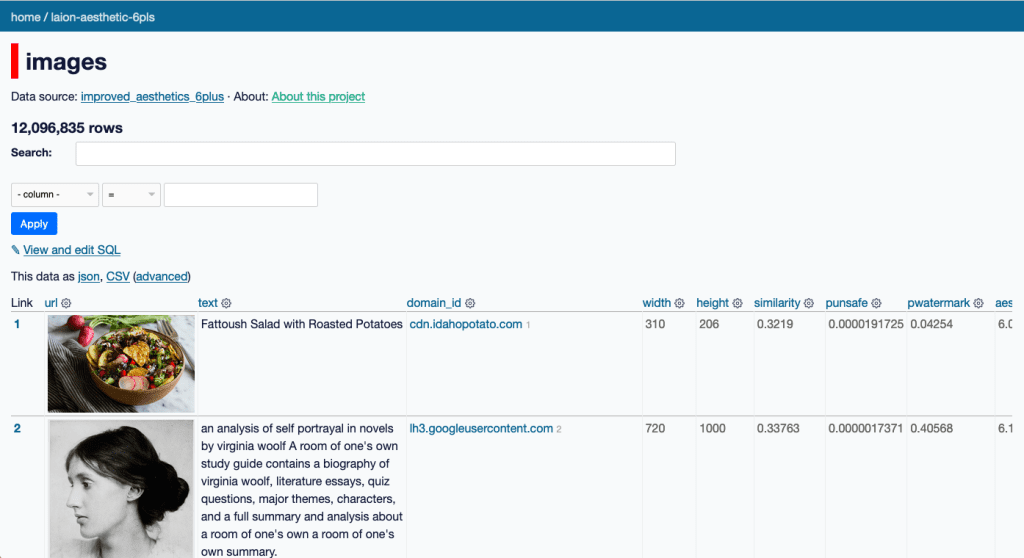
Se calcula que la versión actual de LAION (LAION-5B) contiene 5.800 millones de imágenes. Como no es accesible para cualquier usuario descargar o analizar esta cantidad masiva de datos, dos tecnólogos, Andy Baio y Simon Willison descargaron unas 12 millones de esas imágenes de LAION y construyeron un buscador al que llamaron Datasette para que cualquiera pueda buscar en la base de datos usada para entrenar esta IA.
En ella hemos encontrado los 55 fotógrafos y reporteros gráficos que están al final de este reportaje, pero pueden ser muchos más. Hay que recordar que es sólo un porcentaje del total de imágenes que pueden haber sufrido el plagio de esta IA generativa: un 0,5% de las 2.300 millones de imágenes sobre las que fue inicialmente entrenado.
En su análisis, Baio encontró que casi la mitad de las imágenes, un 47%, provenía de sólo 100 dominios, la mayor parte con origen en Pinterest. Las plataformas con contenidos generados por los usuarios fueron una fuente inmensa de datos de imágenes. Sólo WordPress representa el 6,8% del total (819.000). También hay cantidades importantes de imágenes provenientes de otros sitios de fotos, arte o blogs como Blogspot, Flickr, DeviantArt, Wikimedia o Tumblr. En el dataset hay fotos que fueron tomadas de medios de comunicación, y aparecen imágenes de perfiles de usuarios e incluso registros médicos. En septiembre de 2022, un artista encontró fotos de su cara que habían sido tomadas por su cirujano y pertenecían a su historia clínica.
Las localizó en otro buscador, el de una web llamada “Have I been trained?”. Esta web dice ayudar a los artistas a quitar sus obras plagiadas de los datos de entrenamiento de las IA generativas, pero hay dudas sobre los motivos del colectivo llamado Spawning, que está detrás de esta iniciativa. En Newtral.es no hemos podido verificar qué hacen con los datos introducidos ni encontrar a un artista que haya logrado lo que le prometen.
El doble estándar de las empresas de IA generativas
Las pocas empresas que se dedican a desarrollar IA generativas están recibiendo inversiones multimillonarias y la tendencia sigue en aumento. Aunque han abierto algunas versiones (demos) de sus productos al público, ya están obteniendo ingresos de estas herramientas. OpenAI ha licenciado GPT-3 con Microsoft y esta compañía lo ofrece integrado en sus productos. Si miramos a los usuarios directos, ‘consumidores finales’ de ChatGPT, vemos que su crecimiento ha sido el mayor en la historia de las plataformas de internet, con 100 millones de usuarios activos a los dos meses de su lanzamiento. De ellos, un porcentaje no revelado por la compañía utiliza la suscripción de pago, que cuesta 20 dólares (unos 18 euros) por mes.
Al igual que OpenAI en su acta de principios, los dueños e inversores en estas tecnologías hablan de la AGI y dicen trabajar en su desarrollo guiados por el mejor interés de la humanidad. Los beneficios que nos traerá la IA siempre son conjugados en futuro. En estos discursos suelen mencionar los riesgos de la IA generativa –para salvarnos de ellos– pero no hay referencias ni al plagio ni al daño que están causando estas empresas hoy.
El impacto de la IA está presente actualmente en la huelga de guionistas de Hollywood, que piden regular el uso de IA, no por miedo a que les reemplace sino porque ven cómo reduce sus retribuciones, según recoge Mashable. Lo han incluido porque están viendo cómo se les empieza a pedir que reescriban contenido generado por ChatGPT para que puedan pasar los detectores de IA, y eso se paga a una tarifa menor que un primer borrador de guion.
Ortiz en estos momentos no puede dar cifras de cómo le ha afectado en su trabajo por la demanda que está en curso, pero lo que sí explica es que muchos profesionales a su alrededor están viendo cómo les afecta y empiezan a preocuparse.
El campo de batalla no es el arte: es el negocio
Emad Mostaque es el CEO de Stability AI. Ortiz le ha preguntado en Twitter varias cuestiones relativas a este tema: ¿cómo evitarán que se utilice material con copyright en los datasets? ¿Se está considerando poner estos conjuntos de datos en dominio público? ¿Por qué se utiliza opt-out para los artistas que no quieren que su obra se utilice de esta manera? Mostaque sólo intervino para decir que LAION había sido creado por una organización sin fines de lucro, y que Stability IA financia a LAION, y dejó muchas preguntas sin responder.
Según la ilustradora, el campo de batalla aquí no es el arte. “¿Un artista humano puede vencer a una IA? ¡Por supuesto! La intención está ahí, tienes a una persona comunicándose con otra, una persona no comete errores estúpidos. Pero aquí no se trata de arte, se trata de mercados y negocios”.
Mientras tanto Mostaque sigue diciendo que su objetivo es “Democratizar la IA”. Este es “un concepto contradictorio que no debe confundirse con con la mejora de la accesibilidad a la IA”, advierten investigadores del Centro para la Gobernanza de la IA en Oxford. Ellos han dicho que a menudo no se concreta si con “democratización de la IA” se habla del uso de la IA, el desarrollo de estos modelos, los beneficios económicos que produzca la tecnología o la gobernanza de las IA.
Para Santi Palacios, todo lo que implica la generación de imágenes por IA y los retos que pone por delante, están al margen del plagio. Le parece “increíble que las empresas estén usando imágenes con copyright para crear sus algoritmos y lucrarse con ello. Vamos a tener que pensar cómo afrontar esto y esas empresas van a tener que asumir responsabilidades”, señala.
Lavado de datos en los grandes modelos de lenguaje
Baio además analizó una de las bases de datos (WebVid-10M) con la que Meta entrenó Make-A-Video, su herramienta de IA generativa de vídeos y encontró que también se utilizaron conjuntos de datos académicos no comerciales para entrenar un modelo. Aunque no sabemos si están haciendo actualmente dinero con esta IA generativa y por lo tanto aún no se puede hablar de plagio, Baio no duda en llamar a esto un “lavado de datos de la IA” y denuncia que se ha convertido en una práctica habitual que las empresas tecnológicas que trabajan con IA utilicen comercialmente conjuntos de datos y modelos recopilados y entrenados por entidades de investigación no comerciales, como universidades u organizaciones sin ánimo de lucro. En algunos casos, como el de Stability AI con LAION, financian directamente esa investigación.
Anna Surinyach cree que “quizás con el uso de la IA, cada vez más amplio, tendrá más valor trabajar donde realmente pasan las cosas. Pero que nuestras imágenes alimenten la ‘máquina’ que amenaza con quitarnos ‘la comida’ es surrealista”. Otra fotógrafa, Ana Palacios está a favor de la IA aplicada a las imágenes, siempre y cuando las empresas lo pacten con los autores de las imágenes de las que se nutren y que la audiencia que recibe esas imágenes sepa que es un producto generado con IA.
El CEO de OpenAI, que participó en una reunión con la Casa Blanca en la que se habló de los riesgos de la IA con otros líderes del sector, acaba de decir que trabajan en nuevos modelos de ChatGPT que respetan el copyright, según Axios. Pero aún no sabemos qué pasa con los contenidos con propiedad intelectual que ya han utilizado sin permiso, o qué imágenes han alimentado a DALL-E.
‘Plagio’ masivo en el entrenamiento de las IA generativas
El acceso a la cultura para modificar lo que existe y producir nuevas creaciones impregnó los primeros años de internet, y por eso muchos contenidos tienen licencias que permiten un uso legítimo. Pero ninguna ley califica como uso legítimo la explotación literal de la totalidad del material ajeno para fines propios. Marta Peirano en El País llama al entrenamiento de este modelo de IA una máquina automática de “plagio masivo”, y esta, la nueva guerra del copyright.
¿Se puede ir hacia atrás con la tecnología? “Cuando oigo que la IA ya está aquí, es como si dijeran que la IA va a explotar a la gente y no hay nada que podamos hacer. Y eso está muy lejos de la verdad”, dice Ortiz.
El error, según el pensador Evgeny Morozov, está en llamar Inteligencia Artificial, un término de la guerra fría, a máquinas que “no se basan en reglas abstractas sino en el trabajo de seres humanos reales, artistas, músicos, programadores y escritores, de cuya obra creativa y profesional se apropian esos sistemas con la excusa de querer salvar la civilización”. Explica que “si queremos que esa creatividad siga existiendo, debemos financiar la producción de arte, ficción e historia, no solo los centros de datos y el aprendizaje automático”.
Ante los que dicen que no podemos hacer nada contra el avance de la IA, Ortiz menea la cabeza. “No estoy convencida de que necesitemos automatizar la creatividad. La IA en las ciencias, o en la medicina, tiene mucho sentido, puede ayudar a desarrollar nuevos medicamentos, puede ofrecer otras perspectivas. Pero el espíritu creativo de los humanos no necesita que lo arreglen”, dice Ortiz.
Fotógrafos españoles y latinoamericanos encontrados por Newtral en el sub-dataset de LAION:
Emilio Morenatti, Manu Brabo, Santi Palacios, Anna Palacios, Anna Surinyach, Francisco Seco, Gervasio Sánchez, Pablo Tosco, Samuel Aranda, Susana Girón, Andrés Gutiérrez, Alvaro Barrientos, Daniel Ochoa de Olza, Bernat Armangué, Rodrigo Abd, Enric Martí Folgosa, Manu Fernandez, Ander Gillenea, Alberto Saiz, Israel Lopez Murillo, Pedro Armestre, Antonio Pizarro Rodriguez, Francisco Ubilla, Joan Mateu, Chema Moya, Emilio Naranjo, Alex Caparros, Jorge Guerrero, Aitor Alcalde, Pablo Blazquez Dominguez, Angel Martinez, Josep Lago, Jose Jordan, David Ramos, Juan Naharro Gimenez, Miguel Riopa, Carlos Alvarez, Cristina Quicler, César Manso, Miguel Morenatti, Francesc Catalá-Roca, Jacobo Medrano, Cristina García Rodero, Joan Fontcuberta, Agustín Esmoris, Gonzalo Javier Santile, Victor R. Caivano, Marcos Brindicci, Javier Corbalán, Alvaro Moya Riffo, Iván Alvarado, Carlos Barria, Pilar Olivares, Felipe Dana, Moises Castillo, Gonzalo Fuentes.
Puedes hacer búsquedas directamente en Datasette sobre un porcentaje de imágenes de LAION https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
Foto: Fiona Art
Fuentes
Santi Palacios, reportero gráfico
Emilio Morenatti, fotoperiodista
Karla Ortiz, artista e ilustradora
Santiago Caruso, ilustrador
Anna Surinyach, fotoperiodista
Manu Brabo, fotoperiodista
Ana Palacios, fotoperiodista
Samuel Parra, abogado
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator
Autoría y autoencoders, Santiago Caruso
Inversiones en IA, Our world in data
Emad Mostaque (CEO Stability AI): Democratizing AI
ChatGPT sets record for fastest-growing user base – analyst note
Artist finds private medical record photos in popular AI training data set
Hollywood writers are fighting the studios on AI, but not for the reason you think