Captura de miles de millones de imágenes, videos, audios y textos personales o de obra protegida por derechos de autor y su compilación en datasets para su transformación con modelos de machine learning /deep learning. Sólo los autores y autoras tienen derecho a hacer cualquier transformación de su obra o autorizar a terceros a hacerlo. Pero bajo la apariencia de non profits, las empresas hacen capturas masivas de obras y datos personales y ceden su explotación comercial a otras, que los transforman para la generación algorítmica de derivados de las mismas. Este conjunto de acciones constituye un robo de la propiedad intelectual y de datos personales, además de un data laundering (lavado de datos)
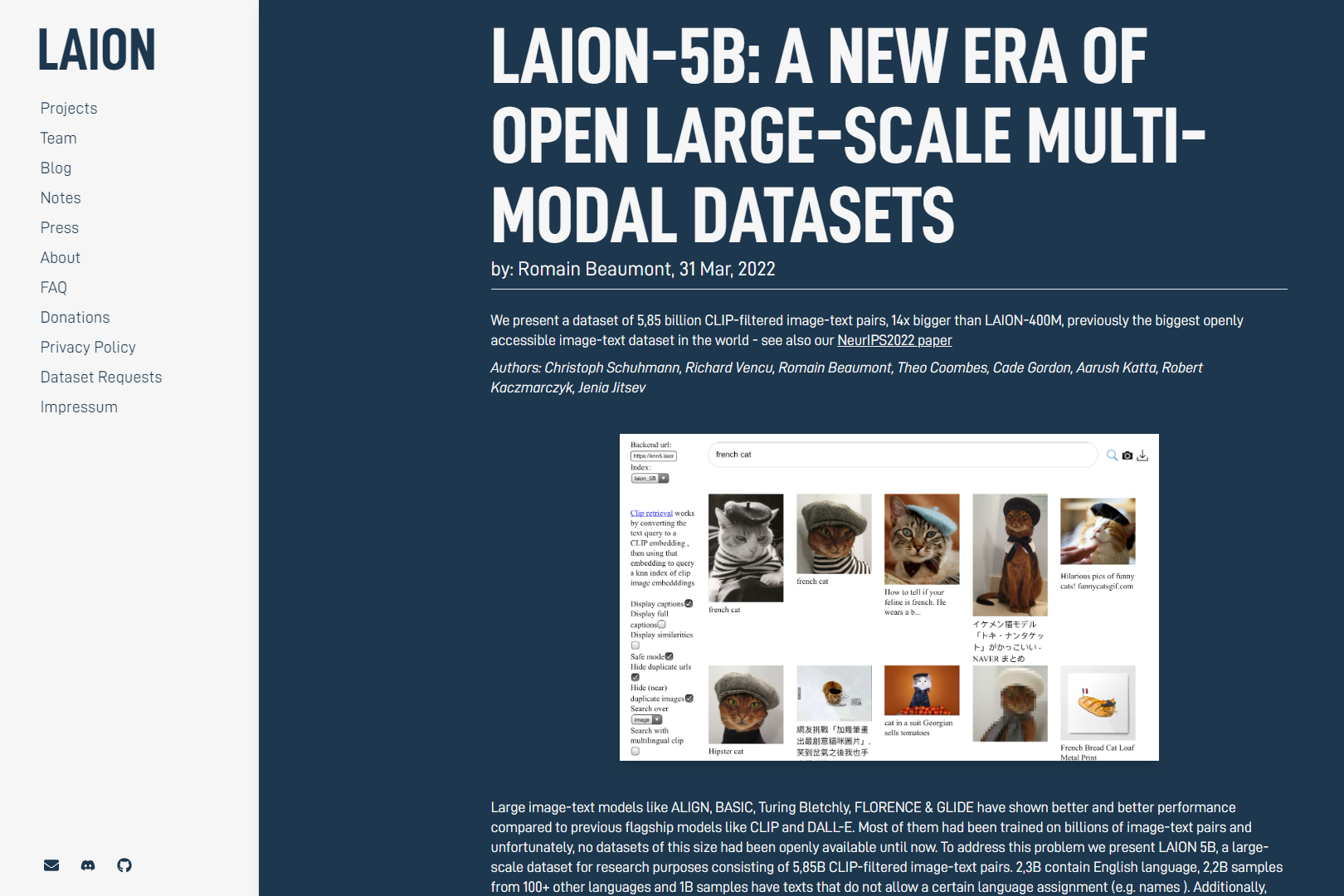
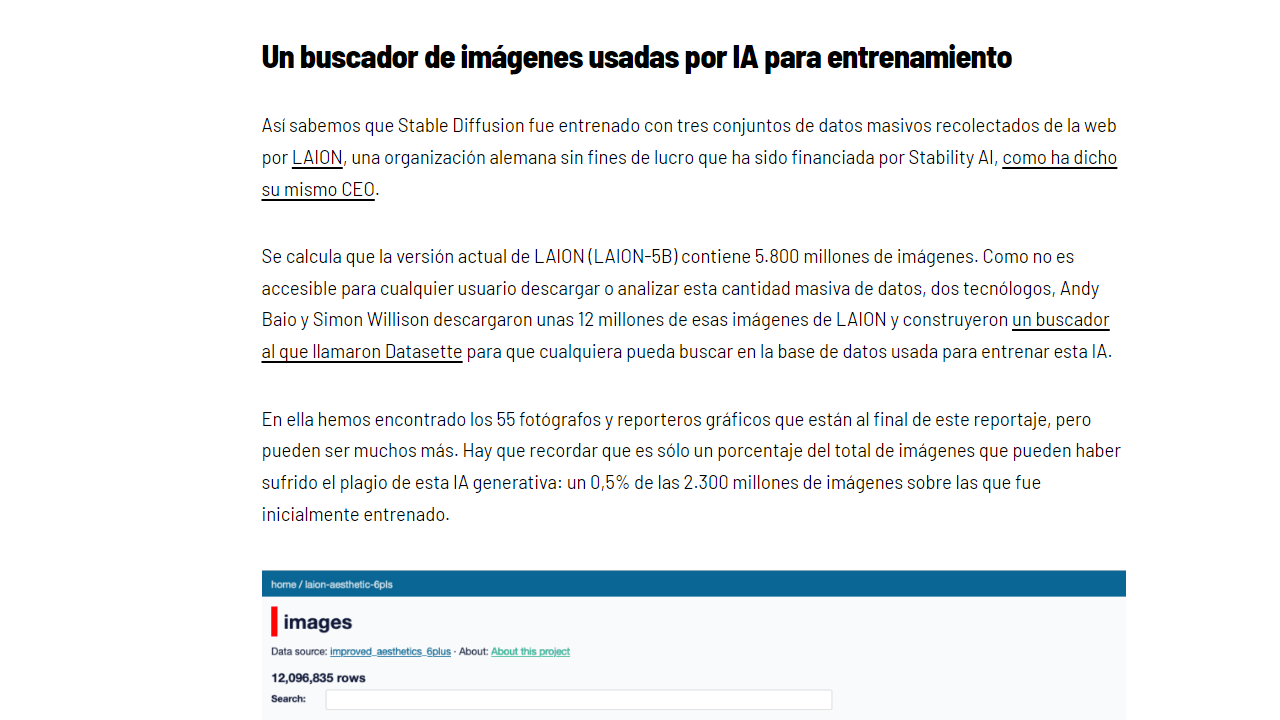
La empresa LAION (Large-scale Artificial Intelligence Open Network) bajo la figura de non-profit obtuvo permisos para hacer raspaje de datos en internet (data scraping) como aparente método de investigación. A través de este procedimiento sistematizaron una base de datos usando un software llamado CLIP, que listó pares de imagen+texto a partir de la captura del exorbitante volumen de 5.8 mil millones de imágenes, cuyos derechos de propiedad intelectual pertenecen a sus creadores o a las personas que figuran en ellas. Pero LAION se ha fungido como facilitador de esa data a terceros, como Stability AI, que fue una de las empresas que la financió en primer lugar.
«Stability AI creó el popular generador de IA, de texto a imagen, Stable Diffusion, financiando su desarrollo, por el grupo de investigación Machine Vision & Learning, de la Universidad Ludwig Maximilian de Múnich. En su informe del proyecto, los investigadores de LMU agradecen a Stability AI por la “generosa donación de recursos informáticos” que lo hizo posible. Los conjuntos de datos masivos de texto+imagen utilizados para entrenar Stable Diffusion, Imagen de Google y el componente de texto a imagen de Make-A-Video tampoco fueron creados por Stability AI. Todos proceden de LAION, una pequeña organización sin fines de lucro registrada en Alemania. Stability AI también financia directamente los recursos informáticos de LAION»
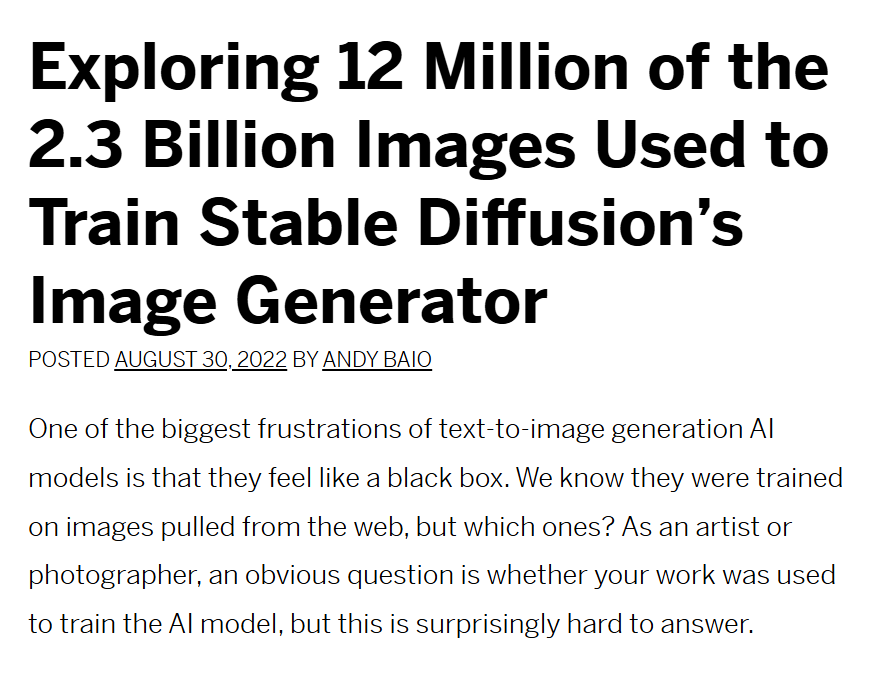
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability – Andy Baio – 2022
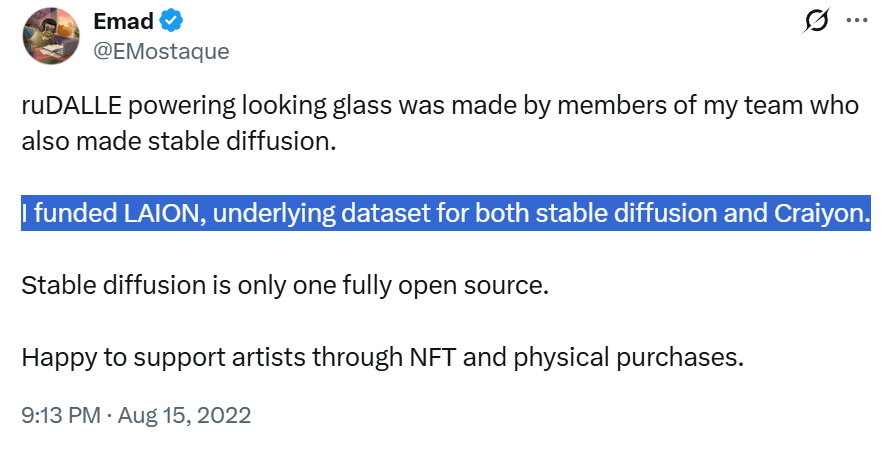
Mohammad Emad Mostaque es el fundador y, actualmente, ex CEO de Stability AI, la empresa desarrolladora de Stable Diffusion. Él mismo lo confirmó en su perfil de X (ex Twitter): «I funded LAION, underlying dataset for both Stable Diffusion and Craiyon»
Así es como las Big Tech crean/financian organizaciones sin fines de lucro, con permiso para crear estos conjuntos de datos o modelos con «fines de investigación»Esto les permitió eludir el reconocimiento de los derechos de autor en la captura inicial de los mismos. Los modelos de datos creados se ceden o venden a empresas con fines de lucro, que los monetizan en API. Estas API se venden a otras personas o grupos comerciales por miles de millones de dólares.
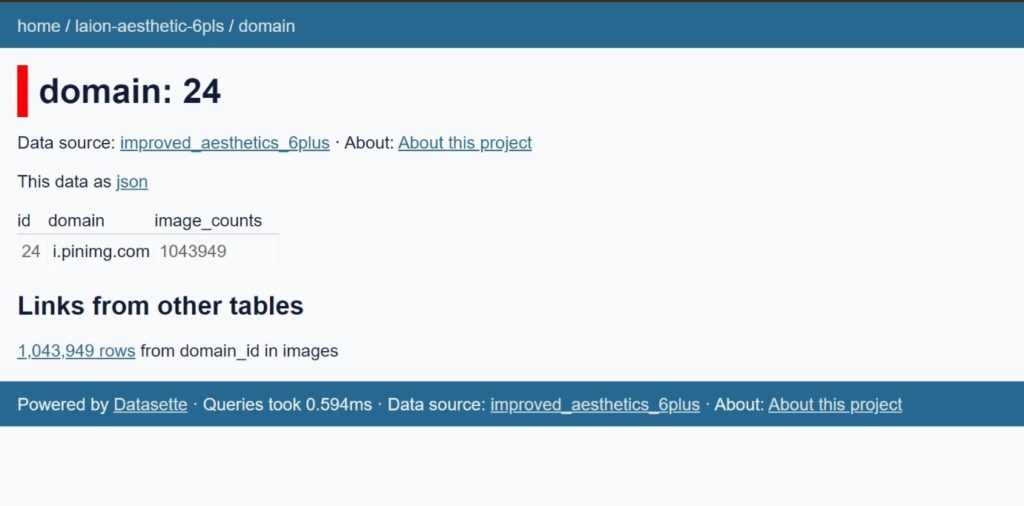
Mike Scholtis publica en Facebook la evidencia de la toma de imágenes que hizo LAION de plataformas de obras de arte como Artstation y Pinterest
“Now I realize that many also like to share from ArtStation on Pinterest and the process is different on Pinterest. We (the users) not only share the image but upload it to the Pinterest server by sharing it. (I don’t talk about uploading on Pinterest, I talk about sharing) So the source file is taken over. https://i.pinimg.com/…….. Let’s see what the database has to say about it i.pinimg.com = 1.043.949 image_counts !!! cdnb.artstation.com = 3001 = image_counts cdna.artstation.com = 3018 = image_counts
Originalmente, las FAQs de Stability I.A. incluían un punto que decía textual:
“Can artists opt-in or opt-out to include their work in the training data? There was no opt-in or opt-out for the LAION 5b model data. It is intended to be a general representation of the language-image connection of the Internet. In the future, for other models, we are building an opt-in and opt-out system for artists and others that services can use in partnership with leading organisations. This model learns from principles, so the outputs are not direct replicas of any single piece”.
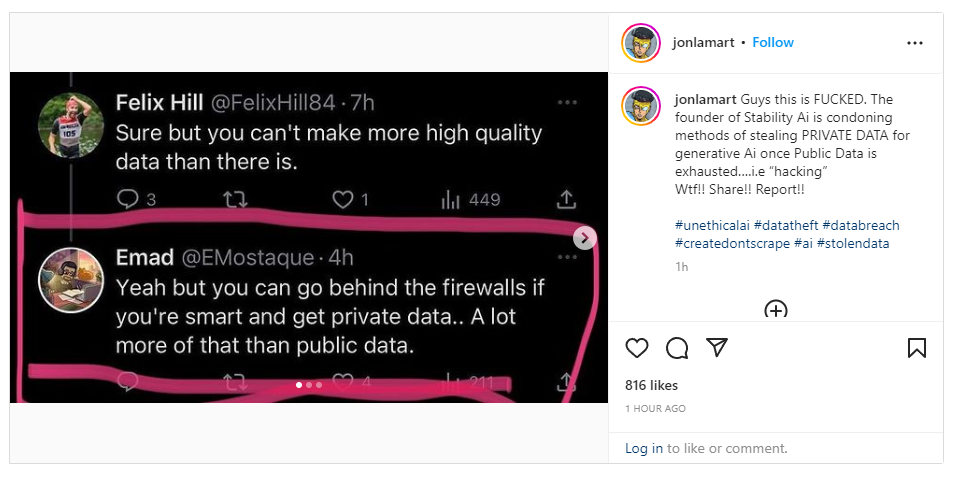
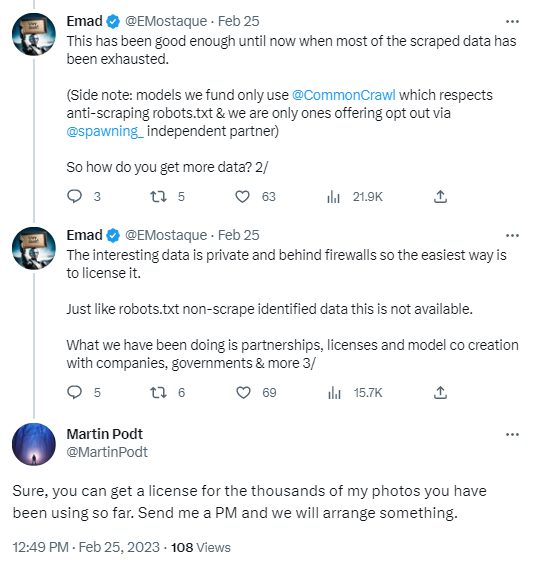
Emad Moustaque about going behind firewallls to scrape more data from people.
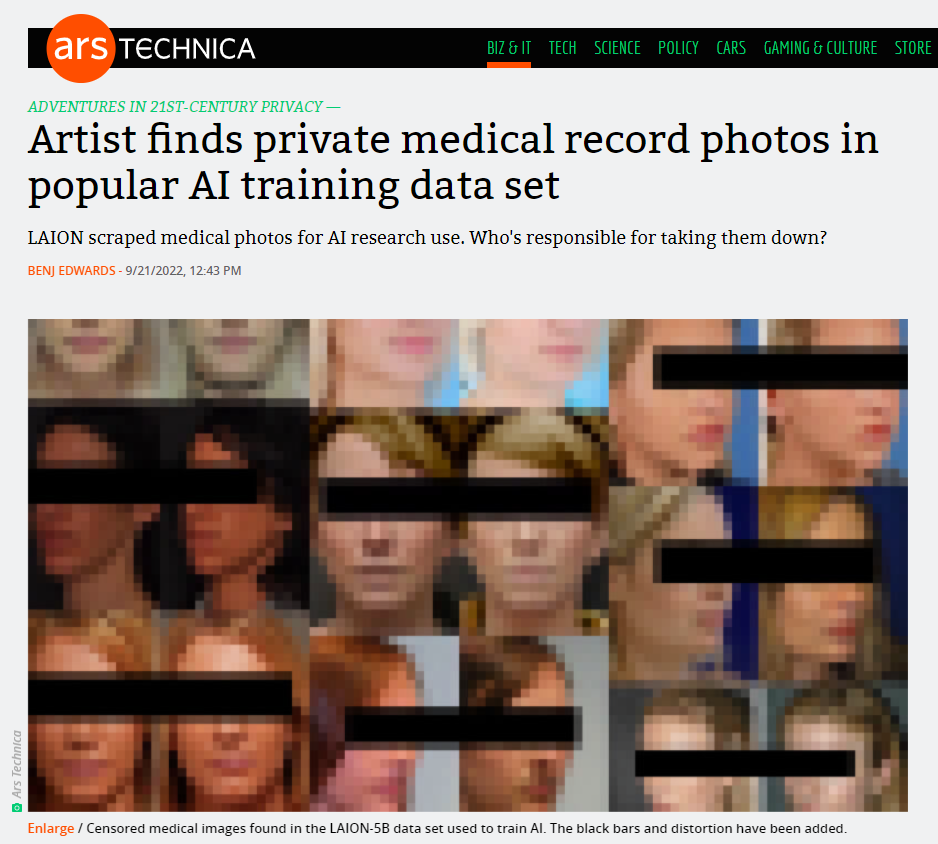
Generative AI is a technology developed based on the theft of copyrighted works.
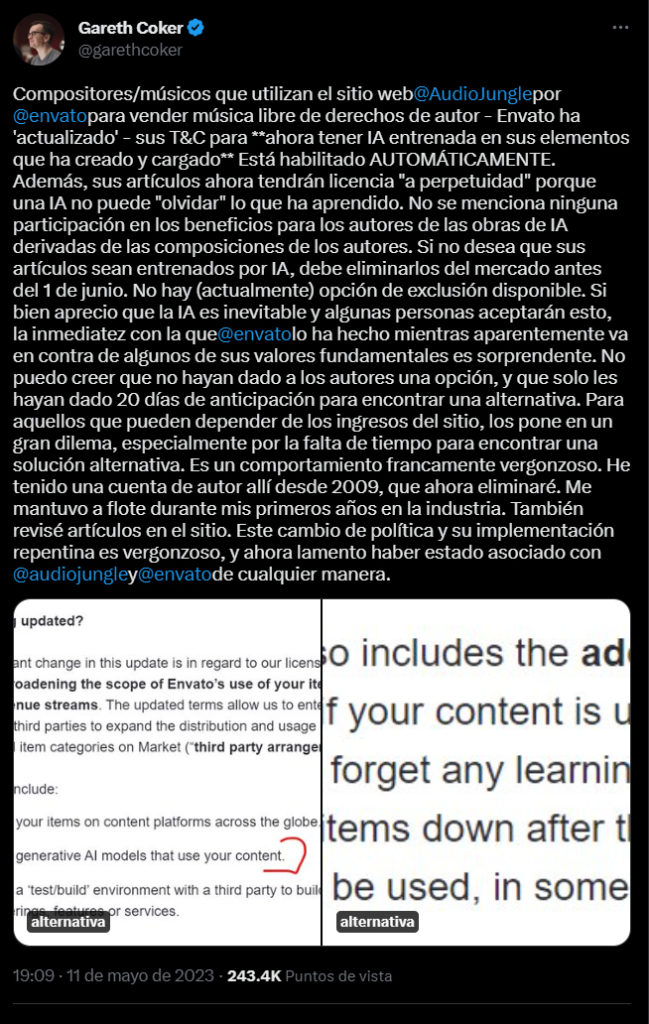
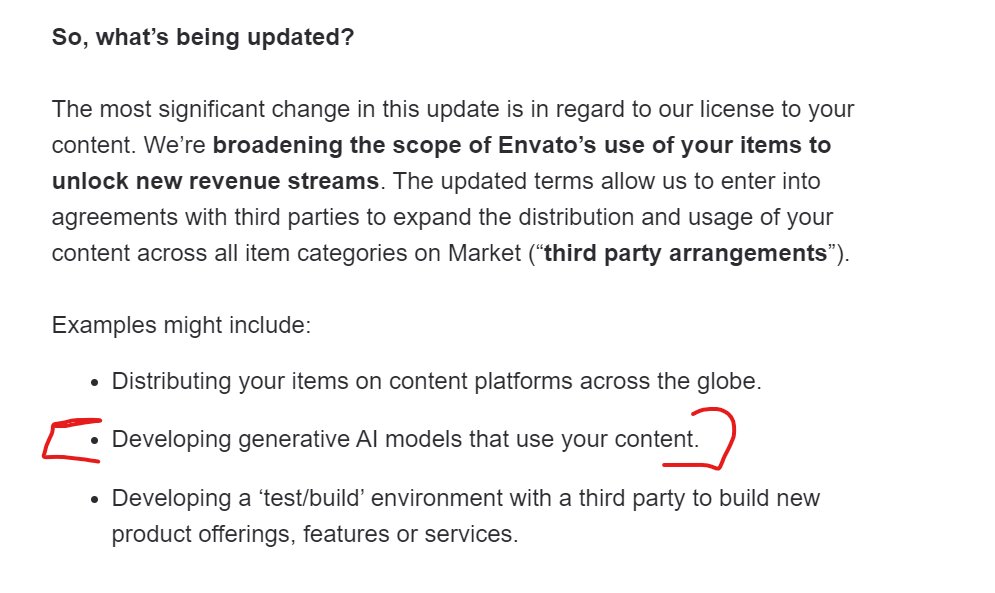
Composers/musicians using the website @AudioJungle by @envato to sell royalty free music – Envato have 'updated' – their T&C's to **now have AI train on your items that you have authored and uploaded**